GPU Primer + Introduction to Vortex
GPU Primer
GPUs implement an SPMD model on a SIMD machine
A GPU's programming model is different from its execution model.
An SPMD model is multithreaded and each thread does the same computation on different data. A SIMT machine can now combine to a single instruction from across all those threads to execute it parallely. Each thread has an independent context (can be restarted or stopped independently) and is the fundamental work unit in a GPU.
Threads that are executing the same instruction (have the same pc) are grouped into warps. Multiple warps along with the warp scheduler and the instruction pipeline form a core. Multiple cores form one node of a GPU.
Good warp scheduling hides latency
Warps are interleaved in the pipeline to hide latecy. If a warp is waiting (because the number of lanes decides cycles per warp it is sent to the queue in the warp scheduler which launches an alternate warp. This can push atleast one warp into the pipeline every cycle. Ideally, each stage in the core's pipeline always has a warp to work on, which hides latency. This way the fetching and scheduling is at the granularity of a warp.
Ideally the scheduled warps have high SIMD utilization, (regrouping can redeem diverging hw threads).
Regrouping can redeem diverging hw threads
Sometimes threads take different control flow paths (branch divergence) and use a mask to set/unset threads. Thread divergence results in low SIMD utilization for a scheduled warp. Though good warp scheduling hides latency, higher SIMD utilization results in warps moving faster through the pipeline.
If a set of threads executing the same instruction (with the same PC) are dynamically grouped into a warp by the hardware. Dynamic grouping of threads ensures grouping of threads that should truly be executing the same instruction. This can be done by forming new warps from warps that are already waiting.
This might need extra hardware to accomplish.
Number of lanes decides cycles per warp
The number of lanes (aka hardware like ALUs) determines how many cycles a warp takes to finish an instruction. This is because each thread maps to one lane, so the number of lanes is the maximum no of threads that can be executed at a time.
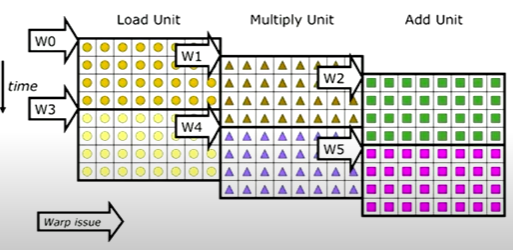
The more cycles warps take, the more needs to be compensated by scheduling because good warp scheduling hides latency.
References
Computer Architecture - Lecture 9: GPUs and GPGPU Programming (ETH Zürich, Fall 2017)
Computer Architecture - Lecture 17: GPU Programming (ETH Zürich, Fall 2019)
Computer Architecture - Lecture 25: GPU Programming (ETH Zürich, Fall 2020)
Vortex
Intro
Vortex is a full-system RISCV-based GPGPU processor (RV32IMF ISA) that can use OpenCL 1.2 or CUDA for its application stack. It supports domain-specific customizations with ISA and pipeline modifications. Recently the subset of the version 0.9 draft of the RISC-V crypto spec was implemented. The result suggested that 4 crypto-accelerated cores exceed the performance of 16 unmodified cores. Vortex is programmable on Intel Arria 10 and Stratix 10.
Resources
Vortex is well documented and has publications listed here and tutorials here